Nel mondo embedded “hard real-time” il codice C/C++ rimane lo standard de facto. Eppure, negli ultimi anni è cresciuto l’utilizzo di approcci low-code e no-code anche su MCU con risorse limitate. Tuttavia, adottare queste soluzioni per MCU non è privo di compromessi. Non è solo una questione di abitudine: è questione di controllo sui registri, prevedibilità temporale, footprint ridotto e facilità di certificazione. La vera domanda non è più “posso usare il low-code su una MCU?”, ma “posso usarlo senza sacrificare affidabilità, prestazioni e sicurezza?”.
Cosa significa davvero low-code nel firmware per microcontrollori
Nel contesto embedded, “low-code” indica l’uso di tool che generano automaticamente una parte importante dell’infrastruttura firmware.
Parliamo di clock tree, configurazione pin, inizializzazione periferiche (ADC, timer, UART, SPI, DMA), setup dell’RTOS con task e priorità, integrazione di middleware come TCP/IP, USB, file system, BLE.
Lo sviluppatore non parte più da un progetto vuoto, ma da una base preconfigurata e coerente con lo schema hardware reale.
In pratica: il progetto firmware diventa un asset aziendale replicabile, non più un “progetto personale” scritto da zero da chi lo sta sviluppando.
No-code: quando il codice nasce dal modello
Il “no-code” fa un passo in più.
La logica applicativa viene descritta in modo grafico o dichiarativo (diagrammi a blocchi, statechart, flussi evento → azione). Da questo modello il tool genera direttamente il codice C/C++ che gira sul microcontrollore.
In questo scenario, l’attenzione si sposta dalla singola riga di codice alla definizione del comportamento formale del sistema: cosa deve succedere, entro quando, in che stato deve andare l’unità in caso di errore.
È un approccio molto usato dove serve certificabilità, perché permette di dimostrare che “in condizione X il firmware reagisce in Y entro N millisecondi”.
Non è esattamente ciò che serve quando non vuoi solo un dispositivo che funziona, ma un dispositivo che risponde a determinati requisiti?
Dove si usano davvero low-code e no-code nelle MCU
Nello sviluppo firmware per microcontrollori, low-code e no-code non sostituiscono il C scritto a mano. Lo affiancano.
Di solito entrano in gioco in tre fasi critiche:
- Bring-up hardware e configurazione MCU
Definizione di pinout, clock PLL, routing DMA, interrupt priority. Qui gli errori manuali costano giorni di debug. - Logica di controllo e stato
Controllo motore, filtri digitali, gestione degli stati di sicurezza, fallback. Qui il modello può diventare codice “MISRA-friendly”. - Orchestrazione di sistema
Task RTOS, stack di comunicazione, aggiornamenti OTA, logging, diagnostica di campo.
In queste tre aree l’errore “umano e ripetitivo” è più probabile e più caro da correggere.

Low-code per microcontrollori: un continuum, non un interruttore
L’adozione del low-code nello sviluppo embedded non è binaria (“tutto generato” o “tutto scritto a mano”). Esiste un continuum di astrazioni. Vediamolo, dal più vicino all’hardware al più astratto.
1. Configuratori hardware e generatori HAL/LL
Esempi noti: STM32CubeMX / STM32CubeIDE (ST), MPLAB Code Configurator e Harmony (Microchip), TI SysConfig, MCUXpresso ConfigTools (NXP), Renesas FSP.
Questi strumenti ti guidano nella scelta di pin, clock, periferiche, DMA e middleware e poi generano codice di inizializzazione coerente. In altre parole, la configurazione dell’MCU non è più “scritta in C” ma “descritta in un file di progetto versionabile”.
2. Modellazione di macchine a stati reattive
Piattaforme come itemis CREATE (ex Yakindu) o Quantum Leaps QM ti permettono di descrivere stati, eventi, transizioni, tempi massimi di reazione, modalità degradate.
Il tool genera codice C/C++ deterministico e leggibile. Risultato: il comportamento del firmware diventa spiegabile, tracciabile e testabile.
Questa visibilità è preziosa quando devi diagnosticare problemi sul campo e capire “perché il dispositivo ha deciso di spegnersi”.
3. Model-Based Design (MBD)
Ambienti come Simulink/Stateflow + Embedded Coder, TargetLink o SCADE permettono di progettare il controllo (PI, FOC, osservatori, filtri digitali), simularlo, validarlo in SIL/HIL e poi generare codice C ottimizzato, spesso già pronto per uso safety. Questo processo è ormai lo standard in settori come automotive e avionico.
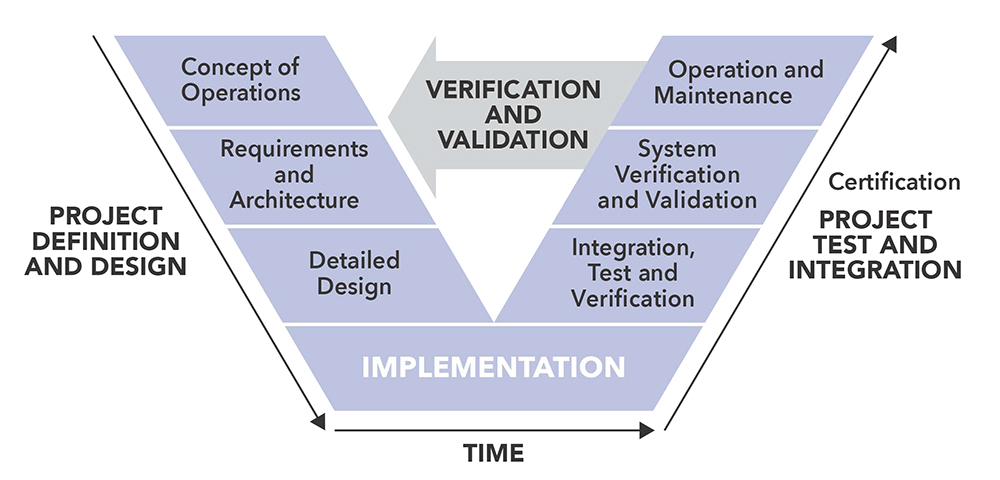
4. Orchestrazione di sistema e integrazione stack
Quando nel prodotto non c’è solo la MCU ma anche un modulo con OS (per esempio Linux embedded), entrano in gioco approcci dichiarativi come devicetree e Kconfig (Zephyr RTOS), oppure stack tipo Torizon/Yocto.

Qui l’obiettivo è descrivere l’hardware e i servizi di sistema come dati, generando poi binding, inizializzazioni e integrazione di rete, filesystem, OTA e telemetria.
Questa modularità diventa fondamentale quando il dispositivo non è più “una scheda singola”, ma un ecosistema con sensori, attuatori, connettività e diagnostica remota.
Perché il low-code embedded risolve problemi pratici?
Configurare una MCU moderna significa decidere moltiplicatori di PLL, priorità NVIC, assegnazione dei pin fisici, bilanciare periferiche che condividono le stesse risorse, rispettare i limiti elettrici di quella board.
Conoscenza condivisa, non tribal knowledge
Un tool low-code centralizza queste scelte in un modello dichiarativo e “versionabile”. Questo modello diventa la “fonte di verità” dell’azienda, non del singolo sviluppatore.
Quanto costerebbe, a lungo termine, mantenere cinque fork del firmware quando potresti rigenerare tutto da una descrizione coerente?
Coerenza architetturale di team (e onboarding più rapido)
Quando i progetti partono tutti dallo stesso generatore, condividono struttura, convenzioni, nomi dei file, gestione degli interrupt, stile di inizializzazione.
Questo abbassa la barriera di ingresso per i nuovi sviluppatori del progetto. Significa anche che puoi distribuire un bugfix critico su più dispositivi senza dover capire prima la filosofia personale di chi aveva scritto quel ramo.
Stack complessi: RTOS, rete, USB, file system
Integrare FreeRTOS, LwIP (TCP/IP), USB CDC, FATFS, logging su SD, watchdog e OTA è notoriamente delicato.
Ogni componente ha aspettative specifiche su heap, priorità, code di messaggi, latenza di interrupt, uso del DMA. I configuratori industriali propagano automaticamente scelte coerenti (priorità, memoria, timer) in tutto lo stack. Questo libera tempo per lavorare sulla logica di prodotto invece che rincorrere condizioni limite non documentate.
In sostanza: preferisci davvero passare giorni a riallineare stack FreeRTOS/LwIP/USB, o preferisci concentrarti sul valore unico del tuo prodotto?
Interruzioni, determinismo e footprint: perdi davvero controllo?
Uno dei timori più comuni quando si parla di low-code per microcontrollori è: “Perdo controllo sul real-time?”.
In realtà, i tool moderni generano ISR (interrupt service routine) molto pulite: l’ISR pulisce il flag dell’evento e passa l’informazione a una callback, a una coda RTOS o a un semaforo. La logica pesante viene gestita fuori dall’interrupt.
Questo approccio mantiene bassi jitter e latenza sugli interrupt più critici, e rende prevedibile il comportamento globale. È vero che una callback HAL aggiunge qualche decina di cicli rispetto al registro scritto a mano, ma per la maggior parte delle funzioni questo costo è irrilevante rispetto al beneficio di avere codice leggibile e rigenerabile.
Le uniche aree dove ancora serve spesso scrivere a mano sono gli ultra-critical control loops: controllo motori ad alta frequenza, gestione RF sotto vincoli di microsecondo, protezioni istantanee.
Footprint: l’overhead è accettabile?
Il codice generato è più generico e porta un overhead, spesso nell’ordine del 5–20% in flash/RAM rispetto a un’implementazione scritta e ottimizzata a mano.
Su MCU con 64–128 KB questo costo è generalmente sostenibile, perché in cambio ottieni velocità di sviluppo, stabilità e ripetibilità. Sotto i 32 KB, invece, ogni kB è critico.
Quindi, la domanda non è “il low-code è troppo pesante?”, ma “su questa MCU specifica posso permettermi quell’overhead in cambio di meno errori e più velocità?”.
E se la risposta è no… posso almeno mantenere la generazione solo per la parte di configurazione iniziale?
Low-code, no-code e sicurezza funzionale (MISRA, ISO 26262, IEC 61508)
Posso usarli in ambienti safety-critical? Sì, a patto di cambiare mentalità: la responsabilità tecnica si sposta dalla singola riga di codice al processo con cui quella riga viene generata.
I tool più maturi possono produrre codice conforme a MISRA-C o AUTOSAR C++. Puoi sottoporlo in automatico ad analisi statica (PC-lint, Coverity, ecc.) a ogni rigenerazione.
Puoi anche tracciare un requisito di sicurezza (“in caso di sovratemperatura spegnere l’attuatore entro 10 ms e andare in stato SAFE”) fino al blocco di modello che lo definisce e alla funzione C generata che lo realizza.
Questo tipo di tracciabilità è esattamente ciò che gli auditor chiedono in settori regolati.
In pratica, quello che difendi non è più “il mio codice è scritto bene”, ma “il mio processo di generazione è sotto controllo e ripetibile”.
Curiosità 1
In alcuni audit ISO 26262, l’ispettore vuole prima vedere la catena requisito → modello → test HIL, e solo dopo chiede di vedere il codice C generato. In pratica il codice non è più il “centro della verità”; è la prova che il processo è stato rispettato.
Come decidere quanto low-code usare (e dove usarlo)
Il principio guida è semplice: automatizza dove l’errore umano è ripetitivo, costoso e noioso da trovare. Scrivi a mano dove le prestazioni in tempo reale sono il vantaggio competitivo del prodotto.
Se hai sezioni con vincoli di pochi microsecondi e jitter minimo (controllo motore, switching di potenza, gestione RF strettissima), quelle sezioni probabilmente richiedono ancora driver ottimizzati a mano, spesso al livello LL o addirittura registro diretto. Ma nulla ti vieta di usare low-code per tutto il resto: inizializzazione, stack di comunicazione, orchestrazione RTOS, logging, diagnostica sul campo, aggiornamenti OTA.
In altre parole, non è più “low-code sì / low-code no”, ma “low-code dove serve struttura ripetibile e C puro dove serve velocità assoluta”.
Varianti di prodotto e manutenzione di lungo periodo
Se lavori su una famiglia di prodotti (revisione A, revisione B, variante con sensore diverso, versione industriale vs consumer), il low-code spesso diventa obbligato.
Senza un configuratore centralizzato, ogni revisione hardware tende a diventare un fork del progetto firmware. Dopo pochi cicli di vita prodotto ti ritrovi con quattro firmware quasi uguali ma incompatibili tra loro.
Curiosità 2
In più di una realtà industriale il repository Git include, accanto al codice sorgente, anche i file di configurazione del tool di generazione e i report di generazione stessa. Il motivo è semplice: quel file È parte del prodotto. Senza, non puoi ricostruire il firmware.
Uno sguardo al futuro del low-code sulle MCU
Stanno nascendo DSL (domain specific language) molto piccole e mirate. Non vogliono descrivere tutto il firmware, ma solo aree importanti e noiose da manutenere: diagnostica di campo, gestione dei power state, protocolli interni, logging strutturato.
Obiettivo: generare codice estremamente compatto, subito pronto per MCU piccole, senza dover importare un framework monolitico.
È interessante perché questa generazione “ultra-mirata” porta automazione anche dove le risorse sono limitatissime.
Possiamo dire che il low-code sta scendendo anche nelle MCU più piccole, non solo salendo verso quelle più potenti?
“Devicetree ovunque”
Zephyr RTOS ha reso normale una cosa che fino a poco fa sembrava fantascienza: descrivere l’hardware in un file dichiarativo (devicetree), lasciare che il sistema generi binding e inizializzazione e poi scrivere solo la logica applicativa.
Questo approccio aumenta la portabilità tra MCU e prepara il firmware a essere trattato in ottica CI/CD, come se fosse software enterprise.
È un segnale forte: l’embedded non è più visto come codice irripetibile scritto a mano. È visto come infrastruttura riproducibile.
Quante aziende si stanno già muovendo in questa direzione senza neanche chiamarla “devicetree”?
Co-design hardware / firmware
Sempre più strumenti cercano di unire decisioni hardware e firmware molto prima del prototipo. Parliamo di tool che ti segnalano conflitti di pin, problemi di timing, limiti di assorbimento, collisioni di periferiche, già in fase di progettazione del layout PCB. Significa ridurre il numero di revisioni hardware necessarie prima di arrivare a una versione stabile di prodotto. Questa integrazione tra elettronica di potenza, firmware real-time e test di produzione è destinata a diventare la norma.
Conclusioni: più conoscenza condivisa
Il low-code e il no-code nel firmware per microcontrollori non sono una scorciatoia facile né un modo per programmare senza competenze. Sono strumenti organizzativi per trasformare decisioni tecniche complesse in un patrimonio condiviso. Non tolgono valore al C scritto a mano: lo concentrano nelle aree dove fa davvero la differenza: permette di trasferire conoscenza, dimostrare conformità, mantenere una famiglia prodotto negli anni e reagire ai cambiamenti hardware senza ripartire da zero. Si tratta di fare in modo che il codice che stai generando oggi resti comprensibile, difendibile e mantenibile anche tra cinque anni, quando quel prodotto sarà ancora sul campo e magari tu starai già lavorando al successore.