
Un gateway IIoT vive dove nessuno torna a guardarlo: quadri elettrici di stabilimento, sale pompe, torri di rete in campagna. Il destino è sempre lo stesso, deve funzionare senza intervento per anni. Nessuno passa a riavviarlo il lunedì mattina, nessuno controlla i LED, nessuno aggiorna manualmente il firmware. La realtà è che una quota significativa dei guasti in campo non viene dal silicio difettoso o dal firmware mal scritto. L’affidabilità di un gateway IIoT non si gioca sulla scelta del microcontrollore o sulla potenza del processore. Fa la differenza tra un MTBF in campo di sei mesi e uno di dieci anni, e si gioca su tre meccanismi: un watchdog hardware esterno progettato bene, un sistema di brown-out detection che intercetta i guasti di alimentazione prima che corrompano lo stato, e una strategia di recovery che riparte sempre da uno stato coerente.
Cosa si rompe davvero in un gateway IIoT lasciato in campo
Prima di parlare di soluzioni vale la pena guardare i failure mode che si osservano nei rientri di garanzia e nei post-mortem degli installatori.
Hang software lenti, dove il firmware non crasha ma smette di rispondere.
Le cause più comuni sono di tre tipi. Memory leak che riempiono l’heap dopo settimane o mesi di funzionamento. Stack overflow causati da chiamate ricorsive in condizioni di errore raro. Race condition su mutex che si manifestano solo quando due interrupt arrivano nell’ordine sbagliato. Il watchdog interno del microcontrollore in questi casi non scatta, perché il loop principale continua a girare e a fare il kick periodico. Il sistema sembra vivo dall’esterno, ma non sta più facendo il suo lavoro.

Brown-out non rilevati
In questo caso la tensione di alimentazione scende sotto la soglia operativa del microcontrollore per durate che vanno da centinaia di microsecondi a qualche millisecondo, e poi torna su. Il chip non si resetta ma può aver eseguito istruzioni con dati corrotti, scritto byte sbagliati in flash, lasciato registri periferici in uno stato indefinito. Il difetto si vede a settimane di distanza, sotto forma di dato sballato o comunicazione persa.
Disturbi EMI
Generati da inverter, motori, contattori e altri carichi induttivi nelle vicinanze. Iniettano transitori sui cavi di alimentazione e sui cavi di segnale. Gli effetti possibili sono diversi: bit che si flippano nelle linee di comunicazione, clock di sistema alterato, reset spuri della MCU.
Corruzione della NVM
Capita dopo un numero elevato di cicli di scrittura concentrati. La flash interna di un microcontrollore tipicamente garantisce 10.000-100.000 cicli per cella, e se il firmware scrive il contatore di pacchetti sempre nello stesso indirizzo, dopo qualche anno la cella muore. A quel punto i dati persistenti diventano inaffidabili e il gateway perde memoria di sé stesso a ogni reset.
Connettori e contatti che si ossidano nel tempo, viti che si allentano
IP rating dichiarato ma insufficiente per l’ambiente reale. Sono problemi meccanici, però l’effetto è lo stesso dei guasti software: il sistema smette di comportarsi come previsto. Un buon firmware non li risolve, ma può rilevarli e segnalarli prima che diventino blocchi prolungati.
Tra questi failure mode, software hang e brown-out sono quelli che pesano di più sui rientri reali, e sono anche le due categorie che si possono prevenire con scelte progettuali fatte all’inizio. Vediamo come.
Watchdog hardware esterno: l’unico che davvero ti salva
Il watchdog timer è la prima riga di difesa contro gli hang software. Praticamente tutti i microcontrollori moderni ne integrano uno, ma il problema è proprio quello: è integrato. Vive nello stesso silicio del processore che deve sorvegliare, condivide alimentazione, clock di riferimento e bus interno, e questo lo rende vulnerabile agli stessi guasti che dovrebbe intercettare.
Watchdog interno: quando basta e quando no
Il watchdog interno della MCU intercetta bene gli hang duri: deadlock della CPU, return address corrotti da stack overflow, loop infiniti in cui nessun task gira più. In questi casi il main loop smette di kickare il watchdog e il chip si resetta da solo, come previsto. Su un gateway IIoT lasciato in campo, però, ci sono tre scenari frequenti in cui il watchdog interno non è sufficiente.

Il primo è l’hang logico: il main loop continua a girare e a kickare il watchdog regolarmente, ma un task essenziale (per esempio il task RF, o quello di acquisizione dati) è bloccato. Dall’interno del watchdog il sistema sembra vivo, ma il gateway ha smesso di fare il suo lavoro. È il failure mode più insidioso che si possa incontrare nei sistemi real-time embedded, perché non lascia tracce visibili se non l’assenza di dati dal sistema centrale.
Il secondo è il brown-out parziale: la tensione di alimentazione scende sotto la soglia operativa nominale della MCU ma resta sopra la soglia minima di funzionamento. Il chip continua a eseguire codice, in modo non deterministico, e i registri di configurazione del watchdog possono perdere coerenza. In questi stati ibridi il watchdog interno può smettere di funzionare correttamente senza che nessuno se ne accorga.
Il terzo è l’EMI severo che può flippare bit nei registri di configurazione delle periferiche, watchdog incluso. È un evento raro su una scheda ben progettata dal punto di vista EMC, ma documentato in application note industriali su MCU esposte ad ambienti elettromagnetici aggressivi.
In tutti e tre i casi serve un osservatore esterno. Un chip dedicato, alimentato separatamente, con il proprio oscillatore e la propria logica di reset, che non condivide nulla con il sistema che deve sorvegliare.
Watchdog windowed e kick condizionato
Un watchdog esterno banale, che si resetta semplicemente con il toggle di un pin a intervalli regolari, ha un difetto importante: non distingue tra un firmware che funziona e un firmware che è entrato in un loop infinito di un task qualunque ma continua a togglare il pin del watchdog perché quel toggle è schedulato su un timer hardware indipendente. Il pin viene togglato, il watchdog non scatta, il gateway resta morto.
Per questo i watchdog hardware industriali seri sono windowed: definiscono una finestra di kick valido, e troppo presto è errore quanto troppo tardi. Se il sistema cerca di kickare prima del limite inferiore, è sintomo che qualcosa sta girando in loop stretto e va resettato comunque.
Il vero salto di affidabilità si ottiene aggiungendo a questo schema il pattern del kick condizionato. Il firmware non kicka il watchdog su un timer indipendente, ma solo dopo aver verificato che tutti i task critici hanno fatto il loro lavoro nell’ultimo ciclo. Si tiene un contatore per ogni task essenziale: task RF, task acquisizione sensori, task logging, task supervisione. Ciascun task incrementa il proprio contatore alla fine di ogni ciclo, e il task di supervisione fa il kick del watchdog solo se tutti i contatori sono cresciuti rispetto al ciclo precedente. Se anche un solo task essenziale si è bloccato, il watchdog non viene kickato e il sistema si resetta. È lo stesso pattern di task monitoring che si trova nei sistemi RTOS safety-critical, applicato qui al contesto meno regolamentato ma altrettanto esigente dei gateway industriali.
Questo schema è la chiave per fermare gli hang logici, quelli in cui il sistema sembra vivo ma in realtà ha smesso di fare la cosa che deve.
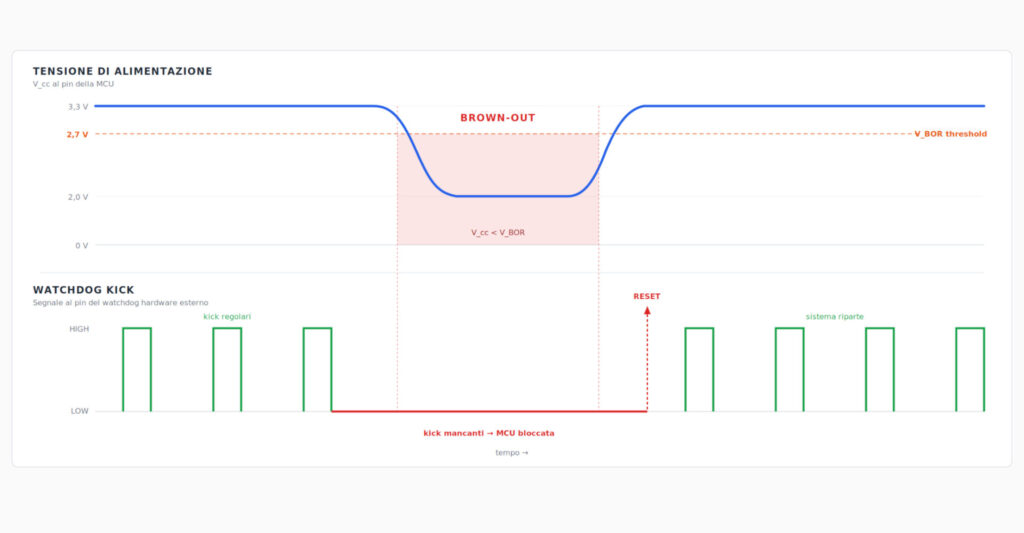
Brown-out detection: il guasto silenzioso che si vede a mesi di distanza
Se il watchdog esterno è la prima riga di difesa contro gli hang, il brown-out detection è la difesa contro un nemico più subdolo. La tensione di alimentazione di un gateway IIoT non è mai stabile come quella di un banco di sviluppo. Le cause di micro-cali e transitori sono molte: partenze di motori sulla stessa linea, contattori che aprono carichi induttivi, fulminazioni indirette, regolatori switching che entrano in modalità burst quando il carico scende sotto la loro soglia di stabilità.
La dinamica del brown-out
Quando la tensione di alimentazione del microcontrollore scende sotto la sua soglia operativa, accadono tre cose nell’ordine. Prima i registri delle periferiche perdono il loro contenuto, in modo non uniforme tra periferica e periferica. Poi la CPU comincia a eseguire istruzioni con dati instabili, perché la SRAM scende sotto la tensione minima di mantenimento. Infine il chip si resetta, o meglio si dovrebbe resettare, perché in molti casi non lo fa pulitamente.
Il problema vero è la zona grigia: nei millisecondi in cui la tensione è sotto soglia ma il chip non si è ancora resettato, il sistema continua a operare con dati instabili. Può scrivere in flash valori sbagliati, mandare comandi alle periferiche con parametri assurdi, accodare messaggi corrotti nei buffer di trasmissione. Quando la tensione torna su e il sistema riparte normalmente, porta con sé corruzioni invisibili che si manifesteranno giorni o settimane dopo.
Soglia BOR interna e supervisori esterni
Tutti i microcontrollori moderni hanno un brown-out reset interno con soglia configurabile, tipicamente tra 1,8 V e 3,0 V. Funziona bene per cali di tensione netti e prolungati, ma ha tre limiti pratici. La soglia è discreta, non sempre allineata con il margine operativo della MCU sotto carico massimo. Il tempo di risposta è dell’ordine dei microsecondi, sufficiente per cali lenti ma non per glitch veloci. E come per il watchdog, vive nello stesso silicio che deve proteggere.
I supervisori di alimentazione esterni risolvono questi tre limiti. Sono chip dedicati al monitoraggio dell’alimentazione, con caratteristiche pensate proprio per le condizioni industriali: isteresi configurabile, soglia precisa al millivolt, tempo di risposta nell’ordine delle centinaia di nanosecondi. Mantengono la MCU in reset finché la tensione non torna stabile entro una finestra definita per un tempo minimo. Sul mercato la scelta è ampia, dai supervisori a singolo canale fino a soluzioni che integrano nello stesso package multiple soglie e watchdog hardware.
Per un gateway IIoT industriale la configurazione robusta combina due livelli: una soglia BOR interna alla MCU impostata sul margine operativo conservativo (per esempio 2,7 V per un sistema 3,3 V), più un supervisore esterno con soglia leggermente più alta (per esempio 2,9 V) e tempo di reset minimo configurabile a 100-200 ms. In questo modo qualsiasi calo di tensione viene intercettato dal supervisore esterno prima ancora di arrivare alla BOR interna, e il sistema riparte sempre da una condizione nota.
Vale la pena ricordare che la qualità del decoupling capacitivo a valle del regolatore influisce direttamente sul comportamento sotto brown-out. Il watchdog esterno e il supervisore sono la rete di sicurezza, ma il primo livello di affidabilità è non averne bisogno.
Stati persistenti e recovery che non perde dati
Quando il watchdog scatta o il supervisore di alimentazione resetta il sistema, il gateway riparte. La domanda chiave è: riparte da dove e in quale stato? Un reset non gestito bene può lasciare dati incompleti in NVM, rimandare configurazioni sbagliate alla rete, o riportare il sistema in uno stato corrotto da cui non esce più. Un recovery gestito bene riparte sempre da una configurazione coerente e perde al massimo l’ultima decina di secondi di dati in transito.
NVM e wear leveling per dati persistenti
Le memorie non volatili integrate nei microcontrollori hanno un numero finito di cicli di scrittura per cella, tipicamente tra 10.000 e 100.000 a seconda della tecnologia. Sembra tanto, ma se un gateway scrive il contatore dei pacchetti ogni minuto per cinque anni, sono 2,6 milioni di scritture sulla stessa locazione. Le celle si usurano, i dati diventano inaffidabili, e a un certo punto il gateway non riesce più a leggere correttamente i propri parametri di configurazione.
La soluzione è il wear leveling: distribuire le scritture su tutta l’area di memoria disponibile invece di concentrarle su poche locazioni. Esistono librerie pronte come LittleFS o l’EEPROM emulation con multi-record buffering, oppure si può implementare uno schema a record circolare in cui ogni nuovo valore viene scritto in una nuova locazione e la lettura cerca sempre il record più recente. La logica è semplice: si ha un blocco di flash di N pagine, si scrive in sequenza, e quando si è all’ultima pagina si torna alla prima dopo un erase. Con un blocco da 64 pagine si moltiplica la vita utile della NVM di 64 volte rispetto a una scrittura concentrata.
Transactional logging e atomicità
Il momento più pericoloso per la NVM è proprio durante la scrittura: se il sistema si resetta nel mezzo di un’operazione di scrittura, può lasciare in flash valori parziali, header senza dati, o dati senza header. Al riavvio il gateway legge un record incompleto e prende decisioni sbagliate basate su dati corrotti.
Il pattern corretto si chiama transactional logging e segue la logica del journaling: si scrive prima un header che marca il record come “in scrittura”, poi si scrivono i dati, e solo alla fine si scrive un marker di commit (tipicamente un CRC calcolato sull’intero record). Al boot il sistema scansiona la NVM e considera validi solo i record con marker di commit presente e CRC verificato; tutti gli altri vengono scartati come scritture interrotte. La penalità è una scrittura aggiuntiva per ogni transazione, che vale ampiamente il guadagno in robustezza.
Il pattern di ripartenza pulita
Un gateway ben progettato segue sempre lo stesso protocollo al boot, indipendentemente dalla causa del reset. Prima legge il motivo del reset dai registri della MCU (power-on, brown-out, watchdog, soft reset, reset esterno) e lo logga su NVM. Poi verifica l’integrità della propria configurazione persistente attraverso il CRC. Se il CRC fallisce, carica una configurazione di fallback nota come “safe” e segnala l’evento al sistema centrale. Se il CRC è valido, riprende le ultime operazioni in transito dal log NVM, restituisce ai buffer i messaggi non confermati, e riapre le connessioni con i parametri salvati.
Questo protocollo deve girare in pochi secondi. Un gateway che impiega trenta secondi a ripartire può perdere i dati che arrivano in quella finestra se non sono buffered a monte (dal sensore, dal modulo radio o dal protocollo applicativo). L’obiettivo realistico è un cold start sotto i 5 secondi e un warm start sotto il secondo, con dati persistenti recuperati intatti in entrambi i casi.
Il logging del motivo del reset è poco discusso ma essenziale per il debugging in campo. Quando si ricevono i log di un gateway che si è resettato 47 volte in una settimana, sapere se sono stati 47 brown-out, 47 watchdog timeout o 47 reset del supervisore esterno cambia completamente la direzione dell’analisi del guasto. Un gateway che si resetta tante volte ma sempre per brown-out indica un problema di alimentazione sul sito specifico, non un bug nel firmware.
Cosa misurare per capire se un gateway è davvero affidabile
L’affidabilità di un gateway IIoT si dichiara facilmente sulla scheda tecnica e si misura difficilmente in campo. Eppure la misura sul campo è l’unico dato che conta.
Tre metriche realistiche da raccogliere e monitorare attraverso il sistema centrale, fin dal primo rollout:
- MTBF osservato in campo per flotta, calcolato come ore di funzionamento totale aggregato sulla flotta diviso il numero di guasti che hanno richiesto intervento fisico o sostituzione. Un buon target per un gateway industriale è 50.000 ore, circa 5,7 anni di funzionamento continuo. Numeri sotto 10.000 ore segnalano un problema strutturale, di solito riconducibile a una di queste cause: hardware sotto-dimensionato, firmware con leak, alimentazione inadeguata, protezioni EMC insufficienti.
- Recovery rate, ovvero la percentuale di reset che il gateway gestisce autonomamente senza intervento umano. È il vero indicatore della qualità del sistema di watchdog, brown-out detection e recovery firmware. In pratica, su flotte industriali ben progettate il valore tipico sta sopra il 99,5%, ovvero su 1.000 reset solo cinque richiedono un intervento fisico. Numeri sotto il 95% indicano che il recovery firmware ha buchi che vanno chiusi.
- Downtime per gateway per anno, somma dei minuti di indisponibilità del singolo nodo in un anno calendario. Si calcola sommando tutti i contributi: reset, recovery, aggiornamenti firmware, riconnessioni di rete. Su un gateway industriale ben progettato il target è sotto i 60 minuti all’anno, che corrisponde a circa 99,99% di availability. È un valore severo, raggiungibile solo se l’OTA update è progettato per non bloccare il servizio, se il recovery è rapido e se la gestione delle riconnessioni di rete è robusta.
Queste metriche sono utili solo se vengono effettivamente raccolte dal primo giorno di rollout e tracciate nel tempo. Serve un sistema di telemetria che riporti al backend ciascun evento rilevante. È un investimento che si ripaga al primo guasto di flotta. Senza questa visibilità l’affidabilità resta una sensazione, non un dato gestibile.
Affidabilità che si progetta, non si dichiara
L’affidabilità di un gateway IIoT non emerge da un microcontrollore migliore o da un firmware più ottimizzato. Emerge da un insieme di scelte progettuali che il datasheet non racconta. La prima è un watchdog hardware esterno windowed, con kick condizionato sui task essenziali. La seconda è un supervisore di alimentazione esterno, con soglia precisa e tempo di reset adeguato. La terza è una NVM gestita con wear leveling e transactional logging. La quarta è un protocollo di boot che riparte sempre da uno stato coerente e logga la causa del reset.
Sono scelte che costano poco in BOM: qualche euro per supervisore e watchdog esterno, qualche settimana di sviluppo firmware aggiuntivo. Ma spostano l’MTBF in campo da mesi ad anni. Il gateway IIoT vive dove nessuno lo guarda, e l’unico modo per renderlo affidabile è progettarlo come se questo fosse il vincolo principale fin dalla prima revisione, non un dettaglio da sistemare dopo il primo rollout problematico.



