A detta degli esperti, l’intelligenza artificiale (AI) sarà, o meglio è già, il motore di una svolta nel risolvere qualsiasi problema indipendentemente dal settore applicativo. Sia esso finanziario, di marketing, attinente alle tematiche della diagnostica medica, alla guida autonoma delle auto, all’ottimizzazione dei processi produttivi, all’assistenza agli anziani e chi più ne ha più ne metta.
Sembra tutto molto eccitante ed è facile lasciarsi trasportare dall’entusiasmo e dal clamore, ma per capirne un po’ di più vale la pena di entrare più a fondo in questo mondo.
Alle basi dell’intelligenza artificiale
Partiamo da una definizione: “l’intelligenza artificiale è un’entità (o un insieme collettivo di entità cooperative), in grado di ricevere input dall’ambiente, interpretare e imparare da tali input e mostrare comportamenti e azioni correlate e flessibili che aiutano l’entità a raggiungere un determinato risultato o obiettivo in un determinato periodo di tempo.”

In parole più semplici: un sistema è intelligente nel momento in cui riesce a compiere un compito di pertinenza umana adottando le stesse strategie di approccio degli esseri umani: imparando dalle esperienze passate e adattando le strategie con l’aumentare delle esperienze (e non per una programmazione predefinita).
Ma esistono una serie di altre definizioni che vale la pena ricordare:
- Machine Intelligence: è un’altra definizione di intelligenza artificiale che fa riferimento al fatto che una macchina sia in grado, nello svolgere il suo compito specifico, di emulare il comportamento umano.
- Machine Learning: fa riferimento alla capacità di un sistema di utilizzare dati per “imparare“, ovvero migliorare progressivamente la propria capacità a eseguire il suo compito specifico, senza esserne esplicitamente programmato. Questo termine è spesso richiamato quando si fa riferimento agli algoritmi per l’AI.
- Cognitive System (sistemi cognitivi): alcune volte definiti “sistemi pensanti“ (thinking systems) che per “imparare” non fanno riferimento solo ai dati, ma anche all’interazione con gli esseri umani.
- Deep Learning: una forma avanzata di machine learning che fa uso di strutture di reti neurali complesse (vedi più avanti). Dobbiamo anche cercare di capire come sono realizzati i sistemi in grado di rispondere a tutte queste definizioni.
L’intelligenza artificiale è iniziata con la ricerca di una struttura computazionale che rassomigliasse in qualche modo alla struttura organizzativa del cervello degli esseri viventi: tantissimi neuroni collegati tra loro in un modo più o meno stretto. Questo ha portato a delineare le reti neurali.
Reti neurali (Neural Network – NN)
Un esempio di rete neurale semplificata, ovvero con un numero limitato di neuroni, è rappresentato in Figura 1.
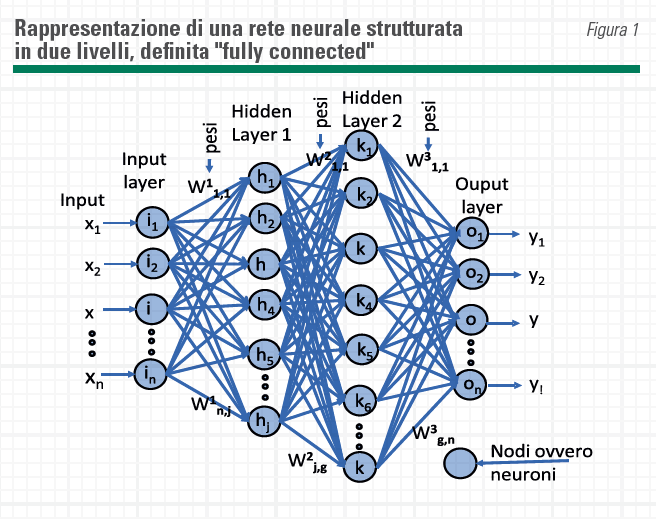
- La rete si compone di: un livello di ingresso (input layer) sono i neuroni che ricevono le informazioni dai sensori che si interfacciano con l’ambiente a cui spetta una prima interpretazione dei dati.
- I livelli interni o nascosti (hidden layer) – nel grafico ne sono mostrati due – che ricevono i segnali provenienti dai neuroni del layer di ingresso o comunque dai livelli che li precedono (la rete è definita feedforward: le informazioni viaggiano sempre da sinistra verso destra).
- Il livello di uscita che, ricevendo le informazioni dal layer interno, rappresenta l’ultimo passaggio dell’elaborazione che poi definisce le uscite della rete.
- In una rete definita “fully connected” ogni neurone è collegato a ogni neurone del livello successivo e a ognuno di questi collegamenti è assegnato un peso ovvero un fattore moltiplicativo con cui l’informazione di uscita dal neurone precedente viene condizionata prima di essere passata al neurone ricevente. Le strutture con più livelli nascosti sono le più complesse e normalmente dedicate al “deep learning“.
Reti neurali convoluzionali (Convolutional Neural Network- CNN)
Una CNN è un caso particolare di rete neurale consistente in uno o più livelli convoluzionali, spesso seguiti da un livello di sottocampionatura (o di pooling), che alla fine presentano uno o più livelli di neuroni completamente connessi (fully connected) (Figura 2).

Lo schema delle CNN nasce dalle considerazioni scaturite dallo studio di come si comporta la corteccia visiva del cervello.
La corteccia è composta da cellule che sono responsabili di rilevare le forme in piccole regioni sovrapposte del campo visivo. Il primo stadio di convoluzione in una CNN svolge il compito delle cellule della corteccia.

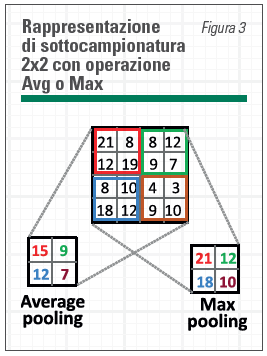
Una tipica configurazione è mostrata in forma ridotta in Figura 3.
Il processo di convoluzione consiste nel fare scorrere – nel caso in figura una matrice di 5×5 – sull’intera matrice di ingresso di 32×32 ottenendo una prima mappa delle caratteristiche. Essa viene successivamente sottocampionata (ogni matrice 2×2 viene sostituita da un solo punto, max o avg dei quattro punti di partenza – Figura 3).
Questi passaggi portano a una matrice 14x14x108, detta feature map, mappa delle caratteristiche, dove vengono evidenziate le caratteristiche elementari della porzione di immagine di partenza come bordi orizzontali o verticali, angoli ecc.
Nelle CNN le dimensioni dei filtri di convoluzione usati per l’estrazione delle caratteristiche (feature) così come i pesi dei layer fully connected, che sono usati per la classificazione finale, vengono determinati durante il processo di apprendimento.
Negli ultimi tempi questo tipo di reti ha assunto una fondamentale importanza nei sistemi di riconoscimento e tracciamento di oggetti, nella comprensione della scrittura manuale e nel riconoscimento vocale.
Come si fa?
Cerchiamo di capirlo con un esempio canonico basato su una rete neuronale impiegata in un sistema di riconoscimento visivo che può eseguire la rilevazione e il riconoscimento di soggetti come illustrato nella Figura 4.

Il punto di partenza è ovviamente la definizione della rete neurale che dovrà essere pensata per rispondere allo scopo dell’applicazione obiettivo. Esistono diversi ambienti di lavoro come Tensorflow [2] di Google, Caffè [3], sviluppato da Yangqing Jia dell’università di Berkeley e dalla relativa comunità, Torch e diversi altri.
Questi sono ambienti di sviluppo, normalmente open source, che mettono a disposizione una serie di strumenti che aiutano a definire, allenare, testare ed utilizzare una rete neurale.
Il passo successivo, che avviene off line, è quello di addestrare la rete sottoponendole centinaia di migliaia di immagini definendole.
Il processo è delineato in Figura 5: dato un input noto alla rete neurale si misura il discostamento tra l’uscita effettiva e quella desiderata e sulla base di questo errore si aggiustano i pesi delle connessioni tra i neuroni ripetendo il processo fino a raggiungere il livello di probabilità richiesto di ottenere il risultato corretto.

Le stesse piattaforme di sviluppo citate in apertura forniscono librerie adatte ai diversi obiettivi della tipologia di riconoscimento desiderata: segnali stradali, animali, veicoli, ecc.
In questa fase è necessaria un’elevata accuratezza che porta ad usare aritmetica a 32 bit in virgola mobile e vengono definiti tutti i coefficienti relativi ai collegamenti di ognuno dei nodi con quelli adiacenti.
Il passo successivo consiste nella conversione della rete da 32-bit in virgola mobile a 8 o 16-bit in virgola fissa che sia in un formato eseguibile in una struttura realizzata con GPU (Graphic Processing Unit), in FPGA oppure in un SoC sviluppato alla bisogna come il Vision Processing Unit (VPU) XM6 di CEVA.
La conversione da virgola mobile a virgola fissa è indispensabile sia per ridurre la necessità di capacità di calcolo che per mantenere le dissipazioni entro limiti ragionevoli.
Il risultato di questa conversione consente finalmente di trasferire la nostra rete, e la relativa capacità di riconoscimento, sul dispositivo target.
A questo punto se colleghiamo il target a una video camera e mostriamo una immagine – per esempio l’immagine di un cagnolino – il sistema risponderà … “guardate: un cagnolino!!”
Il processo di convertire una rete espressa in virgola mobile e già addestrata in una rete equivalente in virgola fissa e in una sequenza di operazioni matematiche eseguibili è estremante difficoltoso ma già alcune società hanno sviluppato “Network Converters” che possono svolgere questo compito automaticamente.