Le Reti Neurali si stanno affermando, sempre di più, nella tecnologia ad ampio raggio. IoT, applicazioni matematiche, giochi d’intelligenza, processi decisionali e quant’altro, possono oggi essere risolti usando queste tecniche di elaborazione. Se prima occorrevano architetture e piattaforme molto esigenti, adesso è sufficiente possedere un modesto sistema embedded per le relative implementazioni. Inoltre, i bassi costi rendono le applicazioni basate sull’intelligenza artificiale accessibili in tutti i settori.
L’apprendimento automatico
L’intelligenza artificiale può essere utilizzata per qualsiasi applicazione, dalla più ludica a quella più impegnativa. L’esempio che segue prevede la creazione e l’elaborazione di un modello matematico che possa prevedere l’andamento dei dati, secondo uno schema ben preciso, fornito in input. Le elaborazioni sono effettuate in Python. In particolare la rete neurale in oggetto provvede a creare un modello capace di prevedere il valore in uscita proveniente da un certo valore in ingresso. La determinazione del modello non avviene ne’ usando un fitting lineare o non lineare ne’ utilizzando la tecnica Montecarlo. Il seguente codice genera tanti punti quanti sono il numero di campioni memorizzati nella variabile SAMPLES. Quindi, esso crea un insieme di valori casuali da una distribuzione uniforme nell’intervallo compreso tra 0 a 15, per simulare il rumore della seguente funzione:

Infine traccia i valori della funzione, visibile nella curva blu, e il relativo rumore casuale, visibile nella curva rossa.

SAMPLES = 5000
x_values = np.random.uniform(low=0, high=15, size=SAMPLES)
y_values = np.cos(x_values)*np.sqrt(x_values)
plt.plot(x_values, y_values, ‘b.’)
plt.show()
y_values += 0.5 * np.random.randn(*y_values.shape)
plt.plot(x_values, y_values, ‘r.’)
plt.show()

Frazionamento dati
L’insieme delle informazioni va adesso frazionato in tre diversi segmenti riguardanti, rispettivamente, l’addestramento, la validazione e il test. Il modello finale è più funzionale quando le previsioni combaciano il più possibile con i dati reali. Il listato sottostante mostra le procedure di frazionamento.
TRAIN_SPLIT = int(0.6 * SAMPLES)
TEST_SPLIT = int(0.2 * SAMPLES + TRAIN_SPLIT)
x_train, x_validate, x_test = np.split(x_values, [TRAIN_SPLIT, TEST_SPLIT])
y_train, y_validate, y_test = np.split(y_values, [TRAIN_SPLIT, TEST_SPLIT])
assert (x_train.size + x_validate.size + x_test.size) == SAMPLES
plt.plot(x_train, y_train, 'b.', label="Addestramento")
plt.plot(x_validate, y_validate, 'y.', label="Validazione")
plt.plot(x_test, y_test, 'r.', label="Test")
plt.legend()
plt.show()

Implementazione e addestramento di un semplice modello
La Rete Neurale è creata tramite l’API Keras, ideale per il Deep Learning. L’addestramento è eseguito attraverso il metodo fit(). Un numero grande di iterazione costituisce sempre una buona soluzione, anche se non conviene esagerare nella quantità. Il seguente codice provvede a implementare e addestrare un semplice modello, con 500 iterazioni.
from tensorflow.keras import layers
model_1 = tf.keras.Sequential()
model_1.add(layers.Dense(16, activation='relu', input_shape=(1,)))
model_1.add(layers.Dense(1))
model_1.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
model_1.summary()
history_1 = model_1.fit(x_train, y_train, epochs=500, batch_size=16, validation_data=(x_validate, y_validate))
predictions = model_1.predict(x_test)
plt.clf()
plt.title('Training data predicted vs actual values')
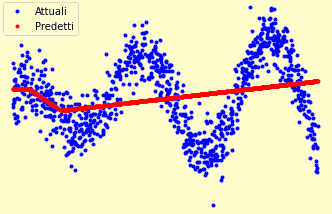
plt.plot(x_test, y_test, 'b.', label='Attuali')
plt.plot(x_test, predictions, 'r.', label='Predetti')
plt.legend()
plt.show()
La procedura può anche impiegare diversi minuti per svolgere l’intero addestramento. Il primo modello creato non soddisfa pienamente lo scopo per cui è stato creato, come si può evincere dal seguente grafico. La rete neurale ha imparato parzialmente le regole di approssimazione. Il modello non risulta abbastanza potente per cui occorre migliorare le sue potenzialità.
Aggiunta di neuroni al modello
Uno dei metodi per migliorare le tecniche di stima e aumentare la precisione di approssimazione del modello è quello di aggiungere uno strato supplementare di neuroni. Un numero molto elevato di neuroni migliora notevolmente i risultati di uscita, avvicinandoli al modello teorico. Oltre ad aumentare la complessità del sistema, crescono anche il numero di parametri, come evidenziato dal seguente codice di addestramento, molto più performante del primo.
model_2 = tf.keras.Sequential()
model_2.add(layers.Dense(16, activation='relu', input_shape=(1,)))
model_2.add(layers.Dense(16, activation='relu'))
model_2.add(layers.Dense(1))
model_2.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
model_2.summary()
history_2 = model_2.fit(x_train, y_train, epochs=500, batch_size=16, validation_data=(x_validate, y_validate))
predictions = model_2.predict(x_test)
plt.clf()
plt.title('Comparison of predictions and actual values')
plt.plot(x_test, y_test, 'b.', label='Attuali')
plt.plot(x_test, predictions, 'r.', label='Predetti')
plt.legend()
plt.show()
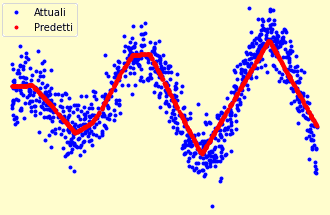
Come si può vedere, stavolta il modello creato utilizzando più neuroni è molto più performante e le previsioni sui dati futuri risultano ben adattate, nonostante la presenza del rumore nei dati. E’ interessante notare le elaborazioni che il sistema effettua a ogni passo, avvicinandosi sempre più alla produzione di un modello ottimale.

Conclusioni
E’ possibile utilizzare Google Colaboratory per semplificare le operazioni di scrittura del codice, all’interno di un browser Web. Si ricordi di specificare le dipendenze nel sorgente, al fine di di installare tutte le librerie necessarie.

Riferimenti
“TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers” , Pete Warden & Daniel Situnayake, O’REILLY